Web crawler
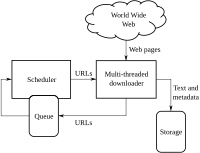
A web crawler is a robot that helps us search for information on the internet. Just like our eyes or fingers, it can see or touch many different places and copy down information that we need.
Imagine all the websites on the internet are like a big jungle. In order to find what we are looking for, we might have to visit every tree and every leaf until we find what we're after - this would take forever if we had to do it ourselves! Web crawlers are like explorers that go into the jungle for us, and quickly scan through all the information in each tree and leaf.
The web crawler starts with a website, and then checks all the links on that website. Then, it follows those links to more websites and checks those ones too. This continues over and over - like a chain reaction where it follows links to more and more websites, until it has visited every single website that it can find. It then takes all the information it has gathered and helps us find the information we need.
For example, if we were searching for information on cats - the web crawler would go through all the websites about cats and look for information about them, such as their breeds, behaviors and habitat. It would then compile all of that information, and present it to us when we search for cats on the internet.
Overall, web crawlers are like super important helpers for us because they help us get to the information we need on the internet.
Imagine all the websites on the internet are like a big jungle. In order to find what we are looking for, we might have to visit every tree and every leaf until we find what we're after - this would take forever if we had to do it ourselves! Web crawlers are like explorers that go into the jungle for us, and quickly scan through all the information in each tree and leaf.
The web crawler starts with a website, and then checks all the links on that website. Then, it follows those links to more websites and checks those ones too. This continues over and over - like a chain reaction where it follows links to more and more websites, until it has visited every single website that it can find. It then takes all the information it has gathered and helps us find the information we need.
For example, if we were searching for information on cats - the web crawler would go through all the websites about cats and look for information about them, such as their breeds, behaviors and habitat. It would then compile all of that information, and present it to us when we search for cats on the internet.
Overall, web crawlers are like super important helpers for us because they help us get to the information we need on the internet.
Related topics others have asked about: