Delimiter collision
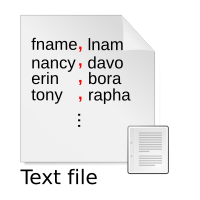
Delimiter collision is a problem that can happen when you use a special character or “delimiter” to separate different parts of information. Imagine you have a puzzle with different pieces: each piece has a different color and shape, and you want to put them together in the right way. To do that, you need something that tells you where one piece ends and the next one starts, right? That’s what a delimiter does: it marks the boundary between two pieces of information.
Now, let’s imagine you want to use a delimiter that also appears in the information itself. Like, say, a comma. You could use a comma to separate different items in a list, for example. But what if one of the items in the list also contains a comma? How do you tell the difference between the delimiting comma and the regular comma that’s part of the item?
This is where delimiter collision comes in. Delimiter collision happens when your delimiter clashes with the data you’re trying to delimit. It can cause all kinds of confusion and errors, because the computer or program you’re using can’t tell which commas are meant to be delimiters and which are part of the data.
For example, let’s say you have a list of people and their ages, and you use commas to separate them:
John, 25
Mary, 32
Bob, 30,5
Oops! Bob’s age got messed up, because he happens to be 30,5 years old – but the computer read the comma after “30” as a delimiter, and thought that the next number was meant to be the start of a new item. So instead of Bob’s age being 30.5, it got split into two pieces: 30 and 5.
There are ways to avoid delimiter collision, such as using a different delimiter that doesn’t appear in the data or encoding the data in a way that makes it clear what’s a delimiter and what’s not. But it’s still an important thing to be aware of, especially if you’re working with lots of data or using different programs that might not handle delimiters in the same way.
Now, let’s imagine you want to use a delimiter that also appears in the information itself. Like, say, a comma. You could use a comma to separate different items in a list, for example. But what if one of the items in the list also contains a comma? How do you tell the difference between the delimiting comma and the regular comma that’s part of the item?
This is where delimiter collision comes in. Delimiter collision happens when your delimiter clashes with the data you’re trying to delimit. It can cause all kinds of confusion and errors, because the computer or program you’re using can’t tell which commas are meant to be delimiters and which are part of the data.
For example, let’s say you have a list of people and their ages, and you use commas to separate them:
John, 25
Mary, 32
Bob, 30,5
Oops! Bob’s age got messed up, because he happens to be 30,5 years old – but the computer read the comma after “30” as a delimiter, and thought that the next number was meant to be the start of a new item. So instead of Bob’s age being 30.5, it got split into two pieces: 30 and 5.
There are ways to avoid delimiter collision, such as using a different delimiter that doesn’t appear in the data or encoding the data in a way that makes it clear what’s a delimiter and what’s not. But it’s still an important thing to be aware of, especially if you’re working with lots of data or using different programs that might not handle delimiters in the same way.
Related topics others have asked about: